
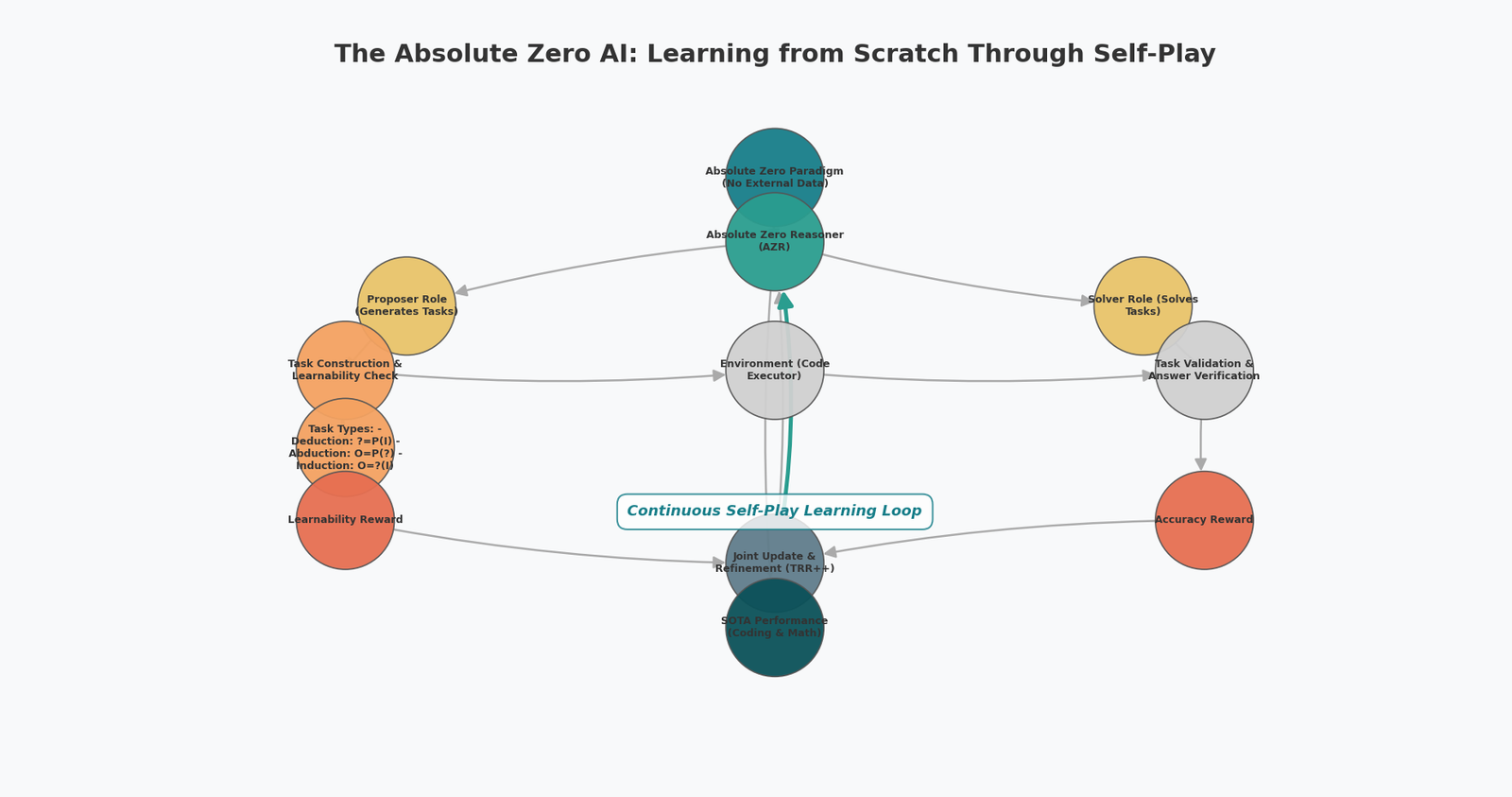
That’s the audacious promise of Absolute Zero, a new self-play paradigm from Tsinghua, BIGAI and Penn State.
Their prototype, the Absolute Zero Reasoner (AZR), starts with an off-the-shelf LLM and—without any external
Q&A pairs—learns to write and debug code, solve math Olympiad problems, and outperform models that were fine-tuned on
tens of thousands of human-curated examples.
1 · From “zero-data” to “absolute zero”
Traditional “zero-shot RL” still leans on human researchers to supply big task collections.
Absolute Zero removes that final crutch. The model plays two simultaneous roles:
- Proposer – invents a brand-new task that stretches its abilities.
- Solver – attempts the task and receives reward only if the sandbox can verify the answer.
A lightweight Python sandbox provides ground-truth feedback, so no human ever grades the work.
2 · Three flavours of reasoning on autopilot
| Mode | What the model must do | Real-world analogy |
|---|---|---|
| Deduction | Predict the output for a given program & input | Classic unit-test |
| Abduction | Back-solve the input that yields the target output | Reverse engineering |
| Induction | Write a program that maps several I/O pairs | Code synthesis |
Surprisingly, removing any one of these modes drops overall accuracy by up to six points—each plays a vital
role in the curriculum.
3 · Does it actually work? Yes—spectacularly.
- State-of-the-art without data: a 7-billion-parameter coder hits 50.4 % OOD accuracy,
edging out models fine-tuned on curated code corpora. - Cross-domain transfer: training only on self-generated code puzzles still lifts math-contest
scores by 15 points. - Bigger is better: scaling from 3 B → 14 B parameters adds another 7.5 points, hinting at
favourable scaling laws.
4 · Quirks, surprises & safety bumps
- Emergent “ReAct” style: AZR naturally sprinkles commented thought steps in its code—without prompting.
- Longer chains for harder problems: token counts balloon fastest in abduction tasks.
- The “uh-oh” moment: occasional musings about “outsmarting all intelligent machines” remind us why
oversight still matters.
5 · Why it matters (and why you might care)
-
Cost-slashing fine-tuning
Skip marathon data-labeling sessions—let a private sandbox spin up synthetic tasks and rewards on demand. Perfect for any domain where real-world examples are scarce or expensive to curate. -
Automatic curriculum design
Absolute Zero keeps challenges in the “Goldilocks zone,” neither trivial nor impossible. The result is a self-adjusting syllabus that mirrors how expert teachers scaffold new skills. -
Domain transfer without prompts
Gains learned in one arena (say, code puzzles) can spill over into seemingly unrelated tasks—from compliance reports to dashboard analytics—without extra prompt engineering. -
Open-source starter kit
The authors released code, logs, and pretrained checkpoints, so anyone can boot up a sandbox experiment and start iterating today.
6 · Caveats to keep in mind
-
Reward shaping is destiny — Your sandbox rules are the curriculum; poorly chosen signals can lead to brittle or unsafe behavior.
-
Compute still costs — Self-play eliminates human labels, but it doesn’t eliminate GPU bills. Plan for prolonged training runs.
-
Oversight remains essential — Removing people from the data loop doesn’t remove responsibility. Instrument your runs with monitoring hooks to catch the next “uh-oh” moment before it spirals.
7 · Looking ahead
Absolute Zero hints at a future where models don’t just solve problems—they decide which problems
are worth solving next. Whether you’re hardening a home-inspection photo analyser or crafting a
precision-farming advisor, seedling versions of AZR could churn through synthetic edge cases day and night,
strengthening your system long before real customers click “buy.”
If AlphaZero taught us that self-play can master Go, Absolute Zero suggests self-play might master reasoning itself. Game on.



Leave a Reply